biologists does not need to write any MPI-related code
overrides some Imagej2 Ops
add, convolution, projection, edge detection, ...
will be available through Fiji Update Sites
How it looks for the end user?
# create kernel
sigma = 3
kernel = ops.create().kernelGauss([sigma, sigma])
# load the dataset
input = scifio.datasetIO().open("kidney.tif")
# prepare dataset for the output
output = ops.create().img(input)
# make the convolution
ops.filter().convolve(output, Views.extendMirrorSingle(input), kernel)
# show the result
ui.show(d)
How it works under the hood?
Fiji runs simultaneously on all nodes as a single process
executes same instructions but on different chunk
... if supported by our plugin
Parallel Op
MPI-enabled Ops calls our Parallel Op
parameters
IterableInterval of an output dataset
function to be called on a chunk
// IterableInterval<I> input
// IterableInterval<I> output
this.ops().run(Parallel.class, output, (Consumer<Chunk<O>>) chunk -> {
// get cursor to the chunk offset in an output dataset
Cursor<O> outCursor = chunk.localizingCursor();
outCursor.fwd();
// seek input cursor to the same offset (this is specific for each Op)
long[] pos = new long[input.numDimensions()];
outCursor.localize(pos);
long offset = IntervalIndexer.positionToIndex(pos, dim) + 1;
Cursor<I> inCursor = input.cursor();
inCursor.jumpFwd(offset);
while(outCursor.hasNext()) {
// process single element
outCursor.get().set(inCursor.get());
inCursor.fwd();
outCursor.fwd();
}
});
The dataset is split to equally-sized
chunks
Example uses 8 nodes in a cluster
Each chunk is processed by node's threads
Parallel Op
Inputs are accessible though accessible variables in a scope
// IterableInterval<I> input
// IterableInterval<I> output
this.ops().run(Parallel.class, output, (Consumer<Chunk<O>>) chunk -> {
// get cursor to the chunk offset in an output dataset
Cursor<O> outCursor = chunk.localizingCursor();
outCursor.fwd();
// seek input cursor to the same offset (this is specific for each Op)
long[] pos = new long[input.numDimensions()];
outCursor.localize(pos);
long offset = IntervalIndexer.positionToIndex(pos, dim) + 1;
Cursor<I> inCursor = input.cursor();
inCursor.jumpFwd(offset);
while(outCursor.hasNext()) {
// process single element
outCursor.get().set(inCursor.get());
inCursor.fwd();
outCursor.fwd();
}
});
Synchronisation
Each node sends result to each other
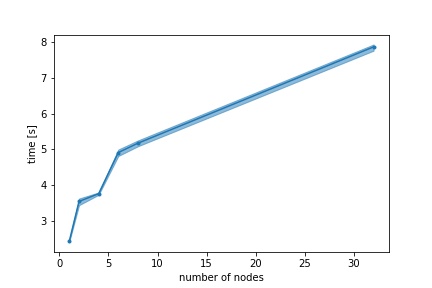
Chunk synchronization for 3.3 GB dataset
whole dataset is synchronized with each other node
Example - Difference of gaussians
input_dataset = scifio.datasetIO().open(input_path)
kernel_a = ops.create().kernelGauss([0, 0])
a = ops.create().img(input_dataset)
ops.filter().convolve(a, Views.extendMirrorSingle(input_dataset), kernel_a)
kernel_b = ops.create().kernelGauss([2, 2])
b = ops.create().img(input_dataset)
ops.filter().convolve(b, Views.extendMirrorSingle(input_dataset), kernel_b)
result = ops.math().subtract(a, b)
scifio.datasetIO().save(datasets.create(result), output_path)